Graphics Processing Unit
Graphics Processing Unit(グラフィックス プロセッシング ユニット、略してGPU)は、コンピュータゲームに代表されるリアルタイム画像処理に特化した演算装置あるいはプロセッサである。グラフィックコントローラなどと呼ばれる、コンピュータが画面に表示する映像を描画するための処理を行うICから発展した。特にリアルタイム3DCGなどに必要な、定形かつ大量の演算を並列にパイプライン処理するグラフィックスパイプライン性能を重視している。現在の高機能GPUは高速のビデオメモリ(VRAM)と接続され、頂点処理およびピクセル処理などの座標変換やグラフィックス陰影計算(シェーディング)に特化したプログラム可能な演算器(プログラマブルシェーダーユニット)を多数搭載している。プロセスルールの微細化が鈍化していることからムーアの法則は限界に達しつつあるが、設計が複雑で並列化の難しいCPUと比較して、個々の演算器の設計が単純で並列計算に特化したGPUは微細化の恩恵を得やすい。さらにHPC分野では、CPUよりも並列演算性能にすぐれたGPUのハードウェアを、より一般的な計算に活用する「GPGPU」がさかんに行われるようになっており、そういった分野向けに映像出力端子を持たない専用製品や、深層学習ベースのAI向けに特化した演算器を搭載したハイエンド製品も現れている。

歴史
1970年代〜1980年代
コンシューマPC向けGPUの起源は1970年代から1980年代のグラフィックコントローラにさかのぼる。当時のグラフィックコントローラは、矩形や多角形の領域を単純に塗り潰したり、BitBlt(Bit Block Transfer、ビット単位でのブロック転送)などにより、2次元画像に対して簡単な描画処理を行うだけであり、その機能と能力は限定的だった。
グラフィックコントローラの中には、いくつかの命令をディスプレイリストとしてまとめて実行したり、DMA転送を用いることでメインCPUの負荷を減らしたりするものもあった。このような専用のグラフィックコントローラを用いずに、DMAコントローラで処理したり、汎用CPUをグラフィック処理専用に割り当てたグラフィックサブシステムを充てるコンピュータも存在した。汎用的なグラフィックス・コプロセッサは古くから開発されてきたが、当時の技術的な制約から安価な製品では機能や性能に乏しく、また高機能なものは回路の規模が増大し非常に高価なものとならざるを得ず、結果的にパーソナルコンピュータへ広く採用されることはなかった。
1980年代から1990年代前半にかけてはBit Block Transferをサポートするチップと、描画を高速化するチップは別々のチップとして実装されていたが、チップ処理技術が進化するとともに安価になり、VGAカードをはじめとするグラフィックカード上に実装され、普及していった。1987年のVGA発表とともにリリースされたIBMの8514グラフィックスシステムは、2Dの基本的な描画機能をサポートした最初のPC用グラフィックアクセラレータとなった。AmigaはビデオハードウエアにBlitterを搭載した最初のコンシューマ向けコンピュータであった。
1980年代後半から1990年代前半の日本国内で広く普及していたPCとしてPC-9800シリーズがあるが、同シリーズのグラフィックの描画に関連するチップにはGDCと、GRCG・EGCがある(CRTCなどもあるが、描画には関係しない)。GDCには直線・円弧・四角塗りつぶしなどの図形描画機能があり、この記事で扱っているタイプのLSIである。GDCは登場時点では比較的高機能・高性能であったが、CPUの性能向上によりその利点は薄くなっていった(そのため、当時の開発者でもそれを正確に把握していない者も多い)。GRCGは複数プレーンへの同時描画(98ではプレーンごとにセグメントアドレスを動かす必要があり面倒だった)や描画時のマスク操作などをハードウェアで行えるもので、EGCはGRCGの強化版(Enhanced Graphic Charger)である。EGCはEPSONが比較的後期まで追随しなかったことや、NECがハードウェアの仕様の公開に非積極的になった以降ということもあり、あまりよく知られていない。さらに、AGDC(Advanced 〜)[1]やEEGC(あるいはE2GC)といったチップに至っては、非公開情報を集めた文献にもその名前以外には殆ど全く情報がない。
1990年代
1990年代に入ると、シリコングラフィックス (SGI) が自社のグラフィックワークステーション用のグラフィックライブラリとして開発・実装したIRIS GLがOpenGLに発展して標準化され、標準化されたグラフィックライブラリとそのAPIに対応したハードウェアアクセラレータ、という図式が登場する。
実装当初のIRIS GLはソフトウェアによるものであったが、SGIでは当初よりこのAPIをハードウェアによって高速処理させる (ハードウェアアクセラレーションを行う) ことを念頭に設計しており、程なくIRIS GLアクセラレータを搭載したワークステーションが登場する。ただし、当初のIRIS GLアクセラレータはまだ単体の半導体プロセッサではなく、グラフィックサブシステムは巨大な基板であった。
1990年代の初めごろ、Microsoft Windowsの普及とともに、グラフィックアクセラレータへのニーズが高まり、WindowsのグラフィックスAPIであるGDIに対応したグラフィックアクセラレータが開発された。
1991年にS3 Graphicsが開発した"S3 86C911"は、最初のワンチップ2Dグラフィック・アクセラレータであった。"86C911"という名は設計者がその速さを標榜するためポルシェ911にちなんで名付けた。86C911を皮切りとして数々のグラフィック・アクセラレータが発売された。
1995年には3DlabsがOpenGLアクセラレータのワンチップ化に成功し、低価格化と高パフォーマンス化が加速度的に進行し始める。また同年に登場したインテルのPentium Proプロセッサの処理能力は同時代のRISCプロセッサの領域に差し掛かっており、このCPUとワンチップ化によって価格を下げたOpenGLアクセラレータのセットは、それまでメーカーに高収益をもたらしていたグラフィックワークステーションというカテゴリーにローエンドから価格破壊を仕掛ける原動力となった。
1995年までには、あらゆる主要なPCグラフィックチップメーカーが2Dアクセラレータを開発し、とうとう汎用グラフィックス・コプロセッサは市場から消滅した。
1995年に3dfxによりVoodooという3Dアクセラレータが発売された。家庭用PCの性能上のボトルネックを考慮してゲーム用に最適化されたGlideというAPIも用意され、家庭用PC上で当時のアーケードゲームに匹敵する品質のグラフィックを実現した。Voodooシリーズは、1990年代後半の家庭用PCゲームの品質向上を牽引したシリーズとなった。
1995年にマイクロソフトがWindows 95とともに開発したゲーム作成及びマルチメディア再生用のAPI群DirectXではさらにグラフィック・アクセラレータの性能が強化された。DirectXのコンポートネントのひとつDirect3Dは当初から3Dグラフィック処理のハードウェア化を想定したレンダリング・パイプラインを持っていた。
1997年当時のグラフィック・アクセラレータはレンダリングのみしかサポートしていなかったが、この頃からZバッファ、アルファブレンディング、フォグ、ステンシルバッファ、テクスチャマッピング、テクスチャフィルタリングなどの機能を次々搭載し、3Dグラフィック表示機能を競うようになった。DVD-Video再生支援機能を備えるチップも現れた。
VDP等の汎用グラフィック・プロセッサについては、カーナビ等の表示用に使用され新たな市場を形成している。90年代後半からは、携帯電話に多色表示がもちいられるようになり、その分野においても有用な市場を形成している。
一方、システムの低価格化を目的に、チップセットのノースブリッジにグラフィックコアの統合を行った、統合チップセットが1997年ころから登場し始める。1999年の「Intel 810」チップセットの登場で、低価格機には統合チップセットの使用が定着し始めた。
3DCGの中核とも言えるジオメトリエンジンは高コストが許容されるグラフィックワークステーションでは専用プロセッサとして搭載されていたが、PCでは長らくCPUが担う機能であった。しかし、ジオメトリエンジンの別名とも言えるハードウェアによる座標変換・陰影計算処理(英: Hardware Transform and Lighting; ハードウェアT&L)が1999年にPC向けにリリースされたDirectX 7にて標準化され[2]、またこのハードウェアT&Lを世界で初めて実装して製品化したNVIDIA GeForce 256を定義する言葉として「GPU」という名称が提唱されることとなった。ハードウェアT&Lの実装によって、NVIDIA社製品は他社製品と比較して突出した高性能を発揮するようになった。これ以後、ジオメトリエンジンとしての機能をCPUに任せる3dfx Voodooシリーズは目立って高性能とは言えなくなった。
2000年代
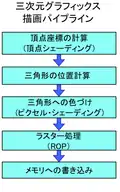
DirectX 8世代では、グラフィックスパイプライン中の一部の処理をユーザープログラマーが自由に記述できるプログラマブルシェーダーが導入されるようになった。プログラマブルシェーダーは頂点シェーダー (Vertex Shader) とピクセルシェーダー (Pixel Shader) の2種類が用意され、頂点シェーダーは頂点座標や光源ベクトルの頂点単位での座標変換および頂点単位での陰影計算(シェーディング)を、ピクセルシェーダーはピクセル単位での陰影計算をそれぞれ担当する設計だった。特に従来の固定機能シェーダーではポリゴン単位(頂点単位)でしか陰影計算を実行できなかったのに対し、ピクセル単位での陰影計算もできるプログラマブルピクセルシェーダーの導入により、表現の自由度と解像度(精細度・品質)が飛躍的に向上した。ただし、シェーダープログラムの記述に使える言語は原始的なアセンブリ言語が基本であり、記述可能なプログラム長(命令数)もごく限られていたため、開発効率や再利用性などの面で課題を抱えていた。なお、頂点シェーダープログラムとピクセルシェーダープログラムを実行するハードウェアユニット(演算器)のことを、それぞれ頂点シェーダーおよびピクセルシェーダーとも呼んでいた。後にNVIDIAでCUDAを開発するIan Buckはこの最初の世代のプログラマブルシェーダーから既にGPGPUに着手しており、厳しい制約下ではあったもののレイトレーシングの高速化についての論文を発表している。
また、この世代になるとマルチテクスチャ、キューブマップ、アニソトロピック(異方性)フィルタ、ボリュームテクスチャなどが新たにサポートされ、HDRIによるレンダリングや動的な環境マッピングの生成が可能になった。動画の再生や圧縮にシェーダーを使う技術も搭載された (Intel Clear Video、PureVideo、AVIVO、Chromotion)。
DirectX 9世代になると、このプログラマブルシェーダーがさらに進化し、シェーダーのプログラムを書くための専用の高級言語であるCg、HLSL、GLSLなどが開発され、シェーダーを物理演算などゲームでの3Dグラフィック表示以外の演算に使うことも多くなった。Windows Vistaに搭載された機能のひとつ「Windows Aero」 (Desktop Window Manager) は画面表示にプログラマブルシェーダー(ピクセルシェーダー2.0)を利用するので[3]、この世代のビデオチップが必須になっている(Windows Aero Glassを使用しなければDirectX 8世代以前のビデオチップでもWindows Vista自体は稼働する)。また、Mac OS XのCore ImageではOpenGLのプログラマブルシェーダーを利用して2Dグラフィックのフィルタ処理を行っている。

統合シェーダーである「Streaming Processor」が128個搭載されている。これにより最大500GFLOPS超で処理する。
DirectX 10世代ではさらに自由度が増し、「シェーダーモデル4.0」 (SM 4.0) に基づくグラフィックスパイプラインが導入され、頂点シェーダーとピクセルシェーダーの間でジオメトリシェーダー (Geometry Shader) によるプリミティブ増減処理を行なえるようになった。ジオメトリシェーダーはOpenGL 3.2でも標準化されている。
グラフィックス描画処理では3次元空間を構成する表現のために三角形を色付けするピクセルシェーディング処理の負荷が、精細度や特殊処理などによって大きく変化するため、固定のハードウェアパイプライン構成ではボトルネックになることが多かった。この制約を解消するために、DirectX 10世代では演算ユニットを汎用化する統合型シェーダーアーキテクチャ (en:unified shader architecture) によって固定のパイプラインの一部をより柔軟な構成に変更した。頂点シェーダーとジオメトリシェーダー、そしてピクセルシェーダーの機能をあわせもつ統合型シェーダー (Unified Shader) [4]を多数搭載して動的に処理を振り分けることによってプログラムの自由度と共にボトルネックを解消し、演算回路数の増加に比例した画像描画処理速度の向上を得た[5]。なお、この統合型シェーダーアーキテクチャによるハードウェアレベルでの汎用化が、GPUにおける汎用演算(GPGPU)の発展と普及を加速させていくことになる。
統合型シェーダーアーキテクチャを採用したNVIDIA GeForce 8シリーズではWindows / Mac OS X / Linux用の標準的な汎用Cコンパイラ環境 (CUDA) が提供され、一方ATI Radeon HD 2000シリーズではハードウェアに直接アクセスできる環境 (Close to Metal) が、そしてRadeon HD 4000シリーズ以降ではATI Stream(Brook+言語と抽象化レイヤーであるCAL)によるアクセス手段が用意されている[6]。これにより科学技術計算やシミュレーション、画像認識、音声認識など、GPUの演算能力を汎用的な用途へ広く利用できるようになった(GPGPU)。また、特定のハードウェアベンダーやプラットフォームに依存しないOpenCLというヘテロジニアス計算環境向け標準規格に続き、米マイクロソフト社からDirectX 11 APIの一部としてGPGPU用APIであるDirectCompute(コンピュートシェーダー)がリリースされた(のちにDirectComputeをバックエンドとするGPGPU向けC++言語拡張・ライブラリとしてC++ AMPも登場した[7])。DirectX 11のシェーダーモデル5.0では、前述のコンピュートシェーダーに加え、頂点シェーダーとジオメトリシェーダーの間に、ポリゴンの細分割・詳細化(サブディビジョンサーフェイス)をGPUで行なうテッセレーションシェーダー(ハルシェーダー、固定機能テッセレータ、ドメインシェーダー)が追加された[8]。テッセレーションシェーダーはOpenGL 4.0、コンピュートシェーダーはOpenGL 4.3でも標準化されている。
なお、主にDirectXに最適化されたGeForceやRadeonなど3Dゲーム向け製品と異なり、業務用ワークステーションなど高い信頼性や耐久性が必要とされる業務用途に特化して設計されたNVIDIA Quadroシリーズ、およびAMD FireProシリーズが存在する。これら業務用製品はDirect3DよりもOpenGLおよびOpenGL対応アプリケーションに最適化されており、CAD、HPC、金融、CG映像、建築/設計、DTP、研究開発分野において採用されている。そのほか、NVIDIA TeslaシリーズやAMD FireStreamシリーズ(のちにAMD FireProに統合)といった、GPGPU専用製品も登場している。
2010年代~2020年代
主なCPUメーカーは、従来のCPU機能だけにとどまらず、1つのCPUチップ内に複数のCPUコア(マルチコア)を搭載すると同時に、画像出力専用回路としてGPUコアも統合した製品を提供するようになった。例えば、米AMDでは「AMD Fusion」構想において1つのダイ上に2つ以上のCPUとGPUを統合し[9][5]、米インテル社でもCore i5、Core i7、Core i3でのSandy Bridge世代から、同様の製品を提供している[10][11][12]。なお、従来型のUMA、つまり単にCPUとGPUのチップを統合して物理メモリを共有するだけでは、CPUとGPUのメモリ空間が統一されることにはつながらない。HSAにおけるhUMAなどのように、CPUとGPUのメモリ空間を統一するためにメモリ一貫性を確保する仕組みが用意されることで初めて、CPU-GPU間のメモリ転送作業が不要となる。また、CPUとGPUの外部メモリが共用されるため、CPUチップの外部メモリバスにはCPUのアクセス帯域に加えてGPUのアクセス帯域も加わる。このため、仮にCPUチップに極めて高い性能のGPUを統合しても、統合チップのメモリアクセス帯域も相応に増強されないと、それがボトルネックとなって性能向上は望めない。
GPU用のメモリ規格として長らくDDR系およびGDDR系が採用されてきたが、2015年6月に発売されたAMD Radeon R9 Fury Xでは、新しい規格系統のHigh Bandwidth Memory (HBM) [13]が世界で初めて採用された[14] [15] [16]。しかし、高性能だが高価格なHBMの採用はコンシューマー用途では進まず、GDDR5の後継規格であるGDDR5XやGDDR6が採用されるようになっている。
2010年代後半にGPGPUという手法が広く普及したことで、HPC分野でもGPUを多用するようになった。特に深層学習(ディープラーニング)ベースのAI用途にGPUの需要が高まっている。VRAMに関しては費用対効果の面から、HPC用途ではたとえ高コストでも広帯域・大容量のHBM、ゲームなどのコンシューマー用途ではたとえ低帯域でも低コストのGDDRという棲み分けが起きている[17]。
一方グラフィックスAPIに関しては、Mantleを皮切りとして、Metal、DirectX 12およびVulkanのように、ハードウェアにより近い制御を可能とするローレベル (low-level) APIが出現することとなった。ローレベルAPIはいずれもハードウェア抽象化レイヤーを薄くすることによるオーバーヘッドの低減や描画効率の向上を目的としており、またマルチコアCPUの活用を前提とした描画あるいは演算コマンドリストの非同期実行といった機能を備えている。また、GPUでリアルタイムレイトレーシングを実現する動きも加速しつつある。2009年にNVIDIA OptiX[18][19][20]が、2011年にイマジネーションテクノロジーズのOpenRL[21]が、そして2018年にマイクロソフトのDirectX Raytracing (DXR) とAppleのMetal Ray Tracingが発表された。NVIDIA GeForce RTXシリーズはDXRのハードウェアアクセラレーションに対応する最初のGPUである。
2020年にはインテルが同社としては1998年に発売した「Intel 740」以来、22年ぶりの単体GPUである「iris Xe Max」を発売し、更に2022年にインテルはPC向けで同社初の本格的な単体GPUである「Intel Arc」を発売した。NVIDIAとAMDの2社がほぼ寡占しているPC向けの単体GPU市場にインテルが本格参戦する状況になった。実態としては最上位でもミドルクラスの性能であり、Resizable BAR 非対応のマシンでのパフォーマンスの大幅低下やドライバの完成度の低さやアイドル時の電力効率の低さなどで主要2社の製品に劣るものの、既に十分使える製品となっているため、主要2社に対するカウンターとしての存在感を示すことには成功したと言える。
GPUの構造
DirectX 10世代以降のGPUは統合型シェーダーアーキテクチャに基づいて設計されており、Intel GMAなどの一部を除きGPGPUにも対応している。
NVIDIA Fermiアーキテクチャの例
NVIDIAのGPUは、統合型シェーダーアーキテクチャを採用したGeForce 8 (G80) シリーズ以降、Warp単位(32ハードウェアスレッド)での並列処理実行が特徴となっている[22] [23]。NVIDIAのGT200アーキテクチャでは、単精度CUDAコア (SPCC) と倍精度ユニット (DPU) が分かれていた[24]が、Fermiでは単精度CUDAコア16個を2グループ組み合わせ、倍精度演算器16個と見立てて実行している[25]。
- ホストインターフェース[26]
- GigaThreadスケジューラ[26]
- グラフィックスプロセッシングクラスタ (GPC)[27]
- ラスタライザ[27]
- ストリーミングマルチプロセッサ (SM)
- テッセレータ (PolyMorph Engine)[27] [30]
- 相互接続ネットワーク
- レンダー出力ユニット (ROP)[28]
- L2キャッシュ[28]
- メモリコントローラ[26]
AMD GCNアーキテクチャの例
AMDのGPUは、Radeon HD 2000~HD 6000シリーズにおいてVLIWを採用していたが、HD 7000シリーズ以降では、グラフィックスだけでなくGPGPUでも性能を発揮できるようにするために、非VLIWなSIMDとスカラー演算ユニットにより構成されたGraphics Core Next (GCN) アーキテクチャを採用している[31]。AMD GPUではWavefront単位(64ハードウェアスレッド)での並列処理実行が特徴となっている。
- リクエスト調停[32]
- スカラーL1キャッシュ[32]
- 命令L1キャッシュ[32]
- コンピュートエンジン
- スケーラブルグラフィックスエンジン[33]
- コンピュートユニット (CU)[32] / 統合シェーダーコア[33]
- クロスバー (XBAR)[35]
- L2キャッシュ[32]
- メモリコントローラ[32]
組み込みシステム
ゲーム機
ゲーム業界においても、1990年代後半から3D描画能力の向上が求められ、ゲーム機(ゲームコンソール)ベンダーはGPUメーカーと共同で専用のGPUを開発するようになった。汎用機であるパーソナル・コンピュータ(PC)用GPUより先行した新機能やeDRAMの搭載で差別化したものが多い。また、汎用化・共通化のための分厚い抽象化層がほとんど不要な専用APIや専用マシン語が使えることもあいまって、同世代における下位や中位のPC用GPUよりも画像処理性能においては高性能である。
本節ではハードウェアT&Lあるいはそれに類する3次元コンピュータグラフィックスパイプラインを有するもののみを列挙する。
- PlayStationに搭載されたGeometric Transfer Engine (GTE)
- SCE製。ハードウェアジオメトリエンジンをPC用GPUより4年ほど先行して搭載している。CPU内のコプロセッサとして動作する。
- なおGTEとは別に、GPUと呼ばれるフレームバッファを扱う2Dグラフィックス処理用のチップも搭載している[36]。
- PlayStation 2に搭載されたGraphics Synthesizer (GS)
- PlayStation 3に搭載されたRSX Reality Synthesizer (RSX)
- PlayStation Vitaに搭載されたPowerVR SGX543MP4+
- Imagination TechnologiesとSCEが共同開発した[38]。
- NINTENDO64に搭載されたRCP
- ニンテンドーゲームキューブに搭載されたFLIPPER
- Wiiに搭載されたHollywood
- AMD製。NEC製造。
- Wii Uに搭載されたRadeon HD
- AMD製。Radeon HD 4000世代[39]。
- ディジタルメディアプロフェッショナルが開発した[40]。
- VideoLogic製。NEC製造。アーキテクチャとしてはDirectX 6世代相当。
- Xboxに搭載されたXGPU
- NVIDIA製。GeForce3と4の中間世代のアーキテクチャ[41]。Xboxは世界で最初にプログラマブルシェーダー対応のGPUを搭載したゲーム機となった。
- Xbox 360に搭載されたXenos
- Nintendo Switchに搭載されたNVIDIA Tegraのカスタマイズ品
- NVIDIA製。カスタム品であることは公式発表されている[43]が、ベースとなったGPUがどの世代なのかは非公表である。
- Vulkan 1.1、OpenGL 4.5以降、OpenGL ES 3.2に対応[44]。
なおXbox One、PlayStation 4においては、それぞれAMD製のx86互換APUのカスタマイズ版が搭載されており、GPGPUの活用とPCゲームからの移植性を重視したアーキテクチャとなっている[45]。
その他
近年、携帯電話やカーナビゲーションシステムの表示機能の高度化が著しく、組み込みシステムにおいて用いられていたVDPに代わって、OpenGL ES対応のプログラマブルシェーダーを搭載したGPUが採用されることが増えてきている。特に使用メモリと消費電力を抑える要求から、PowerVRのシェアが高い。
「GPU」という名前
「GPU」は、1999年にNVIDIA Corporationが、GeForce 256の発表時に提唱した呼称である[46] [47]。それまでビデオカード上の処理装置は「ビデオチップ」や「グラフィックスチップ」と呼ばれていたが、GeForce 256はハードウェアT&Lを世界で初めて搭載し、3次元コンピュータグラフィックスの内部計算および描画処理におけるCPU側の負荷を大幅に軽減するコプロセッサとしての地位を確立したことから、NVIDIA社は「Graphics Processing Unit」と命名した。
GPUと同様の名称として、Visual Processing Unit (VPU) が存在する。「VPU」は、3Dlabs Inc.が、Wildcat VP(量産品としては世界初の汎用シェーダー型設計のGPU)の発表時に命名した[48]。なお、VPUの呼称に関しては、ATI TechnologiesがRadeon 9500/9700の発表時に提唱したと誤解されることがある[49]が、実際は、3DlabsのWildcat VPの発表が先行している。また、ATIがVPUの呼称を使ったのは、当時は3Dlabsと提携していたからでもある。
現在はAMD (旧ATI) も主にGPUの呼称を使用している。
GPUとは別の分類だが、Intelは2019年から、画像認識などのコンピュータビジョンの処理に特化したプロセッサとしてVision Processing Unit (VPU) という名称を使っている。「Intel Movidius Myriad X VPU」は、AIで利用されるニューラルネットワークを高速かつ低消費電力で実現できるエンジンとハードウェアアクセラレータを搭載する、AIアクセラレータである[50]。Meteor Lake世代のプロセッサではVPUを統合することが予定されている[51]。VPUに画像認識処理をオフロードすることで、CPU/GPU負荷を下げることが可能となる。
統合GPU
一般に、チップセットに搭載されているオンボードグラフィックスプロセッサおよびCPU内蔵GPU(統合GPU、integrated GPU: iGPU)のグラフィック機能は、単体チップ型のGPU(ディスクリートGPU、discrete GPU: dGPU)に劣るが、消費電力やコスト面では有利である。このため、主にオフィススイートやインターネットアクセスなどを中心とした高性能が必要ない用途が想定され、低価格が求められる業務用端末(クライアント)機向けや、低発熱・低消費電力が求められるノートパソコンなどでは単体チップのGPUではなく、統合GPUが多く搭載されている。比較的高性能なGPUを使用するゲーム機でもコストダウンを目的としてGPUの統合化が進んでいる。スマートフォンやタブレットに使用されているSoCもCPUとGPUをひとつのチップに統合している。
統合GPUでは、ビデオカードと違って専用のVRAMを持たず、メインメモリの一部をGPUに割り当てるユニファイドメモリアーキテクチャが採用されているが、通常はCPUとGPUのメモリ空間が分離されており、お互いのデータを直接参照することはできない。そのため、事前にソフトウェアレベルあるいはドライバーレベルでのデータ転送処理が必要となる。AMD APUはHSAのhUMAをサポートすることで、CPUとGPUのメモリ空間をハードウェアレベルで統合しており、従来のユニファイドメモリアーキテクチャよりもヘテロジニアス・コンピューティングに適した形態となっている[52][53]。CPUとGPUはそれぞれ得意分野が異なるものの、CPUはコアあたりの性能向上が頭打ちになってきているため、伸びしろのあるGPUにダイの面積を割いて総合的な演算性能を向上させることは理にかなっている[54]。
GPU単体の製品のラインナップも、エントリ向けの低価格なローエンドから、価格と性能のバランスがとれたミドルレンジ、過酷な要求にも耐えうる高性能を持つハイエンド、そして価格を度外視して最高性能を求めるユーザー向けのウルトラハイエンドと様々である。また、主にゲーミング用途を想定したコンシューマー向けや、業務用途を想定したプロフェッショナル・エンタープライズ向けなどに差別化されている。しかし高性能なGPUの利用を前提とするAeroを搭載したWindows Vistaの登場以降、チップセット内、およびCPUパッケージ内に統合されているGPUコアの性能が向上してきたため、GPU単体の製品の主力は3Dゲームの快適なプレイやCADオペレーションあるいは3DCG制作におけるプレビュー用途を想定した、比較的高価で高性能なものへとシフトしている。単体GPUは主にデスクトップPC向けのビデオカード上に実装されたものとして提供・利用されているが、ゲーミング向けの高性能ノートPCなどでは、CPU内蔵GPUだけでは性能的に不十分なため、別途マザーボード上に強力な単体GPUと専用VRAMを実装しているものもある[55]。
外部GPU
外付けの専用ボックス内にグラフィックスボードをスタッキングし、Thunderboltのような高速インターフェイス規格でPCに接続する形態(外部GPU、external GPU: eGPU)も登場している[56][57][58]。ノートPCや一部のベンダー製デスクトップPCは、CPUやGPUを交換することはできず、拡張性に乏しい。外付けボックスを利用して高性能なeGPUをシステムに追加することで、この欠点を補うことができる。利用には対応OSが必要となる。
GPU開発企業
- AMD
- DisplayLink(USBのVGA出力やDVI出力用のICを開発している。ただし、これは一般的にGPUとは認識されていない)
- インテル(1990年代後半にIntel 740という単体GPUを手掛けた後、単体GPUから撤退し、その後は統合GPUのみ手掛けていたが、2020年に単体GPUに再参入した)
- Matrox(PC・コンシューマー向けの新規の自社GPU開発からは撤退し、他社製GPU採用に転向した[59]が、産業用の製品開発は継続されている)
- NVIDIA
- Moore Threads(中国の新興GPUメーカー)
他社へのライセンス供与のみを行なう企業
過去にGPUまたはビデオチップを手がけていた企業
ここにソースの記載がない企業は日本語もしくは英語版Wikipediaのリンク先でソースを確認されたい。
- 3dfx (Voodooシリーズなど。2000年末にNVIDIAに買収された)
- 3Dlabs(PERMEDIAシリーズやP10など。現在は低消費電力のメディアプロセッサを手がける)
- ALi(下記ArtXによる統合GPUの他、nVIDIAからRIVA TNT2のコアの提供を受けてAladdin TNT2という統合GPUも開発した事がある)
- ArtX(1990年代後半~2000年代前半にかけて、統合GPUのコアの部分を開発。主にALiの統合GPUとしてリリースされた。ATIによって買収済。ゲームキューブのGPUのコア部分を担当したことが一番有名)
- ATI Technologies (2006年にAMDに買収された。ATIブランドは買収後しばらく存続していたがAMDブランドに統一された[61])
- Chromatic Reserch(1990年代後半にMPACT2というMPEGデコーダ内蔵のGPUを開発した事がある。ATIによって買収済)
- Cirrus Logic(1990年代前半~半ば頃にCL-GD54xxシリーズというローエンドGPUを開発していた。売却したグラフィック部門資産の変遷は、Magnum Semiconductor→GigPeak→Integrated Device Technology→ルネサスエレクトロニクス)
- チップス・アンド・テクノロジーズ 1997年にインテルに買収された[62]。
- Evans & Sutherland(1990年代後半に、三菱電機と共同で「REALimage1200」「REALimage3000」というOpenGL系GPUを開発していた)
- Intergraph(INTENSE 3DシリーズというGPUを開発していた[63]。グラフィックハードウェア生産部門であるINTENSE 3Dを3DLabsに売却後、ヘキサゴンに買収される)
- Macronix(今はフラッシュメモリの会社だが、1990年代後半に一時期Turbo3というGPUを自社で開発していた時期がある[64])
- NEC(1990年代後半にImagination Technologies/VideoLogicのPowerVR/PowerVR2のGPU製造を受託していた事がある。詳しくはPowerVRやドリームキャストの記事を参照)
- NeoMagic(1990年代半ば~2000年頃までMagicGraph128/256シリーズでノートPC向けGPUを開発していたが、2000年にPC向けからは撤退)
- Number Nine Visual Technology(Imagine128シリーズやTicket to Rideシリーズなど。1999年にS3によって買収済)
- Rendition(1990年代後半にVeriteシリーズというワークステーション向けGPUを開発していた。Micronによって買収済)
- S3 Graphics(ViRGE/DXやDeltaChromeなど。単体GPU・チップセット統合GPUともに手掛けていたが、現在は撤退している)
- SGI (IRIS Graphics, RealityEngine, CRM, InifiniteRealityといったチップセットを開発していた[65][66]。1999年にグラフィックス部門をNVIDIAに売却[67])
- SiS(SiS 315やXabreなど。単体GPU・チップセット統合GPUともに手掛けていたが、現在は撤退している)
- STマイクロエレクトロニクス(NECの後にImagination Technologies/VideoLogicのGPU製造を受託していた企業。KYRO II SEをもって撤退。詳しくはPowerVRの記事を参照)
- Trident Microsystems(Blade XPやXP4など。2000年代前半にXGI Technology Inc.にグラフィックス部門を売却)
- Tseng Labs(ET4000/ET6000というDOS向けGPUを開発していた。グラフィック部門をATIに売却)
- Weitek(POWER9000/9100というワークステーション向けGPUを開発していた。ロックウェルに買収される)
- XGI Technology Inc.(VolariシリーズというGPUを手掛けていたが、2006年にパソコン向けからは撤退し、組み込み向けに移行)
- アイ・オー・データ機器(GA-1024Aなど、PC-98向けに自社でGPUを開発していた時期がある[68])
- ソニー・コンピュータエンタテインメント(PlayStation向けにGeometric Transfer Engine (GTE)を、PlayStation 2向けにGraphics Synthesizer (GS)を開発。ゲーム機の項目も参照)
- ハドソン(PCエンジン向けにHuC6270を開発。HuC62の記事も参照)
脚注
- 小口哲司他 (1987年). “μPD7220後継のグラフィックス・コントローラLSI, コピーや塗りつぶし機能を強化 - 日経エレクトロニクス1987.2.23” (PDF). Oguchi R&D. 2020年11月15日閲覧。
- Microsoft releases DirectX 7.0 | Windows Server content from Windows IT Pro
- Schechter, Greg (2006年3月19日). “DWM's use of DirectX, GPUs, and hardware acceleration” (英語). Greg Schechter's Blog. 2009年2月14日閲覧。
- 【レビュー】初の統合型シェーダーアーキテクチャ「GeForce 8800シリーズ」を試す (1) 新アーキテクチャで登場したG80 | マイナビニュース
- 日経エレクトロニクス 2007/10/8 「プロセサはマルチ×マルチへ」
- AMDのGPGPU戦略は新章へ - ATI Streamの展望、DirectX Compute Shaderの衝撃 (1) Radeon HD 4000シリーズでネイティブGPGPU | マイナビニュース
- MicrosoftがGPGPU開発向けC++の拡張「C++ AMP」を発表 - 多和田新也(AFDSレポート)、PC Watch、Impress(2011年6月17日付配信、2012年3月24日閲覧)
- テッセレーションの概要
- 現実路線へ修正されたAMDのFUSION - 後藤弘茂のWeekly海外ニュース、PC Watch、Impress(2007年12月25日付配信、2012年3月24日閲覧)
- Intelの次期CPU「Ivy Bridge(アイビーブリッジ)」を裸にする - 後藤弘茂のWeekly海外ニュース、PC Watch、Impress(2012年3月2日付配信、2012年3月24日閲覧)
- Intel NehalemとAMD FUSION 両社のCPU+GPU統合の違い - 後藤弘茂のWeekly海外ニュース、PC Watch、Impress(2007年10月11日付配信、2012年3月24日閲覧)
- CPUとGPUの境界がなくなる時代が始まる2009年のプロセッサ - 後藤弘茂のWeekly海外ニュース、PC Watch、Impress(2008年12月2日付配信、2012年3月24日閲覧)
- 5981_High_Bandwidth_Memory_HBM_FNL - High-Bandwidth-Memory-HBM.pdf
- 【レビュー】初のHBM搭載ビデオカード「Radeon R9 Fury X」を試す - PC Watch
- これが“4096”の性能だ:“Fiji”と“HBM”の実力を「Radeon R9 Fury X」で知る (1/5) - ITmedia PC USER
- Hot Chips 27 - AMDの次世代GPU「Fury」 (1) HBMを採用したAMDのGPU「Radeon R9 Fury」 | マイナビニュース
- 株式会社インプレス (2018年3月20日). “【後藤弘茂のWeekly海外ニュース】 Intelなどプロセッサベンダーがけん引するHBM3規格” (日本語). PC Watch 2018年11月12日閲覧。
- NVIDIA® OptiX アプリケーション・エンジン | NVIDIA
- NVIDIA® OptiX Application Acceleration Engine | NVIDIA
- GTC - NVIDIA「OptiX」を解説、レイトレーシングはインタラクティブの時代へ (1) なぜ、今、レイトレーシングなのか | マイナビニュース
- 4Gamer.net ― PowerVRのImaginationが“ハイエンドGPU”の設計に着手。ハイブリッドレンダリングハードウェア,そして新API「OpenRL」とは?
- NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE P.44 IEEE 2008年
- ホワイトペーパー; NVIDIA の次世代 CUDA™コンピュートアーキテクチャ: Fermi™
- An Introduction to Modern GPU Architecture P.44 NVIDIA
- NVIDIA GPUの構造とCUDAスレッディングモデル
- NVIDIA (2009年). “Whitepaper; NVIDIA's Next Generation CUDA™ Compute Architecture: Fermi™ (V1.1)”. pp. 7-8. 2015年12月5日閲覧。
- ■後藤弘茂のWeekly海外ニュース■ DirectX 11でも強力なNVIDIAの新GPU「GF100」 PC Watch 2010年1月19日
- GPU Computing Applications P.42 NVIDIA 2011年
- NVIDIA (2009年). “Whitepaper; NVIDIA's Next Generation CUDA™ Compute Architecture: Fermi™ (V1.1)”. p. 11. 2015年12月5日閲覧。
- 4Gamer.net ― NVIDIA,Fermi世代の次期GeForce「GF100」グラフィックスアーキテクチャを発表
- AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute P.3 2011年12月21日
- AMD GRAPHIC CORE NEXT P.10 AMD 2011年7月
- AMD GRAPHIC CORE NEXT P.39 AMD 2011年7月
- AMD GRAPHIC CORE NEXT P.24 AMD 2011年7月
- AMD GRAPHIC CORE NEXT P.33 AMD 2011年7月
- 【特別企画】歴代家庭用ゲーム機を軒並み分解――TGS2008「ゲーム科学博物館」より(7ページ目) | 日経 xTECH(クロステック)
- 後藤弘茂のWeekly海外ニュース - PLAYSTATION 3のグラフィックスエンジンRSX
- PS Vitaで採用されるGPUコア「PowerVR SGX543MP4+」のImaginationに聞く「+」の意味。PowerVRは次世代ゲーム機への採用も目指す!? - 4Gamer.net
- 【西川善司】Wii UのGPU性能と新型コントローラに秘められた「コアゲーマー求心」の裏戦略 - 4Gamer.net
- [CEDEC 2012]3DSはまだその実力を100%発揮できていない!? 3DSが搭載するGPUコア「PICA200」の詳細 - 4Gamer.net
- 後藤弘茂のWeekly海外ニュース - NVIDIAチーフ・サイエンティスト インタビュー(下)
- 3Dグラフィックス・マニアックス (5) GPUとシェーダ技術の基礎知識(5) | マイナビニュース
- NVIDIA Gaming Technology Powers Nintendo Switch | NVIDIA Blog
- Conformant Products - The Khronos Group Inc
- 【後藤弘茂のWeekly海外ニュース】PlayStation 4のAPUアーキテクチャの秘密 - PC Watch
- CreativeからGeForce 256搭載ビデオカードが登場 - AKIBA PC Hotline! 1999年10月9日号
- GeForce 256
- 3Dlabs Wildcat VP760 Datasheet
- ATIがDirectX 9に対応したVPU「RADEON 9700」をリリース
- 5G時代のエッジに求められるVPUとは?米インテル担当者に聞く | 日経クロステック(xTECH)
- Intel、次世代のMeteor LakeにVPUを統合予定。第13世代CoreでLE Audio対応も - PC Watch
- 【後藤弘茂のWeekly海外ニュース】CPUとGPUのメモリ空間を統一するAMDの「hUMA」アーキテクチャ - PC Watch
- 【後藤弘茂のWeekly海外ニュース】AMD Kaveriのメモリアーキテクチャと今後のAPU進化 - PC Watch
- CPU と GPU の比較: 違いを理解する | Intel
- GeForce RTX 30 シリーズ ノート PC - NVIDIA
- Razer Core X - Thunderbolt™ 3 eGPU
- Mac で外付けのグラフィックプロセッサを使う - Apple サポート (日本)
- Mac で Blackmagic eGPU を使う - Apple サポート (日本)
- Matrox、NVIDIAのカスタム版Quadroを採用したビデオカード - PC Watch
- Appleから利用停止宣告を受けたImaginationの今 - EE Times Japan
- 4Gamer.net ― ATIにお別れ。AMD,ATIブランドを統合し,GPUは「AMD Radeon」に
- ASCII. “インテルとATIが広範なクロスライセンス契約──RADEON統合チップセット登場も”. ASCII.jp. 2023年6月22日閲覧。
- Intergraph - 古典コンピュータ愛好会
- Macronix - VideoChips
- ASCII. “業界に痕跡を残して消えたメーカー CG業界を牽引したSGI (1/4)”. ASCII.jp. 2023年6月22日閲覧。
- “sgistuff.net : Hardware : Graphics”. www.sgistuff.net. 2023年6月22日閲覧。
- EETimes (1999年8月10日). “SGI graphics team moves to Nvidia”. EE Times. 2023年6月22日閲覧。
- 1991年 もっと大きい画面が欲しい よりリアルに高速描画したい(アイ・オー・データ機器)
外部リンク
- 柿本正憲:「GPUの起源と進化」、GDEP, 2021年3月記事。
- GPU移行 GPU移行に関するポータルサイト